OpenData Labs
Engineering insights and technical deep dives from the OpenData team.
VisualizationOpen Source
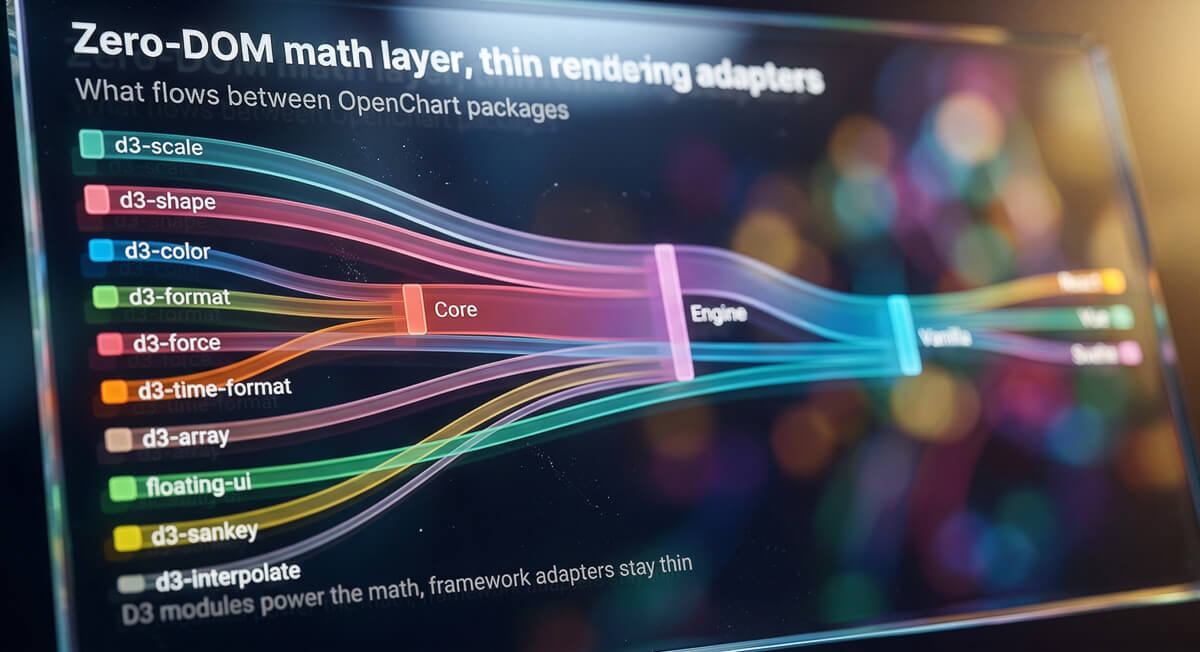
OpenChart Is Now Open Source
The charting library behind OpenData's visualizations is now free and open source. Specs-driven, headless, framework-agnostic, and built for publication-quality output.
Riley Hilliard·Mar 25, 2026·6 min










